Os ácidos nucleicos armazenam e transmitem a informação genética, enquanto vitaminas atuam como cofatores essenciais. Este capítulo integra esses dois grupos, destacando o fluxo da informação genética e o papel das vitaminas na atividade enzimática. A compreensão desses elementos é crucial para conectar genética e metabolismo.
8.1 Estrutura química dos nucleotídeos e suas propriedades #
A compreensão da estrutura química dos nucleotídeos estabelece o ponto de partida para toda a biologia molecular, pois são essas unidades que sustentam, ao mesmo tempo, o armazenamento da informação genética e uma parte significativa da bioenergética celular. Em nível molecular, os nucleotídeos representam uma convergência elegante entre química orgânica, termodinâmica e função biológica, reunindo em uma única entidade estrutural três componentes fundamentais: uma base nitrogenada, uma pentose e um ou mais grupos fosfato [Molécula].
As bases nitrogenadas constituem o núcleo informacional dessas moléculas. Elas são classificadas em dois grandes grupos estruturais: purinas e pirimidinas. As purinas, representadas pela adenina e pela guanina, apresentam uma estrutura bicíclica, formada pela fusão de um anel imidazólico com um anel pirimidínico. Já as pirimidinas — citosina, timina e uracila — possuem um único anel heterocíclico. Essa diferença estrutural não é meramente descritiva; ela condiciona diretamente a forma como essas bases interagem entre si, especialmente por meio de ligações de hidrogênio altamente específicas, que mais tarde permitirão o pareamento complementar no DNA [Figura]. Esse padrão de complementaridade, embora discutido em profundidade em seções posteriores, já encontra sua base aqui, na geometria e na distribuição eletrônica dessas estruturas.
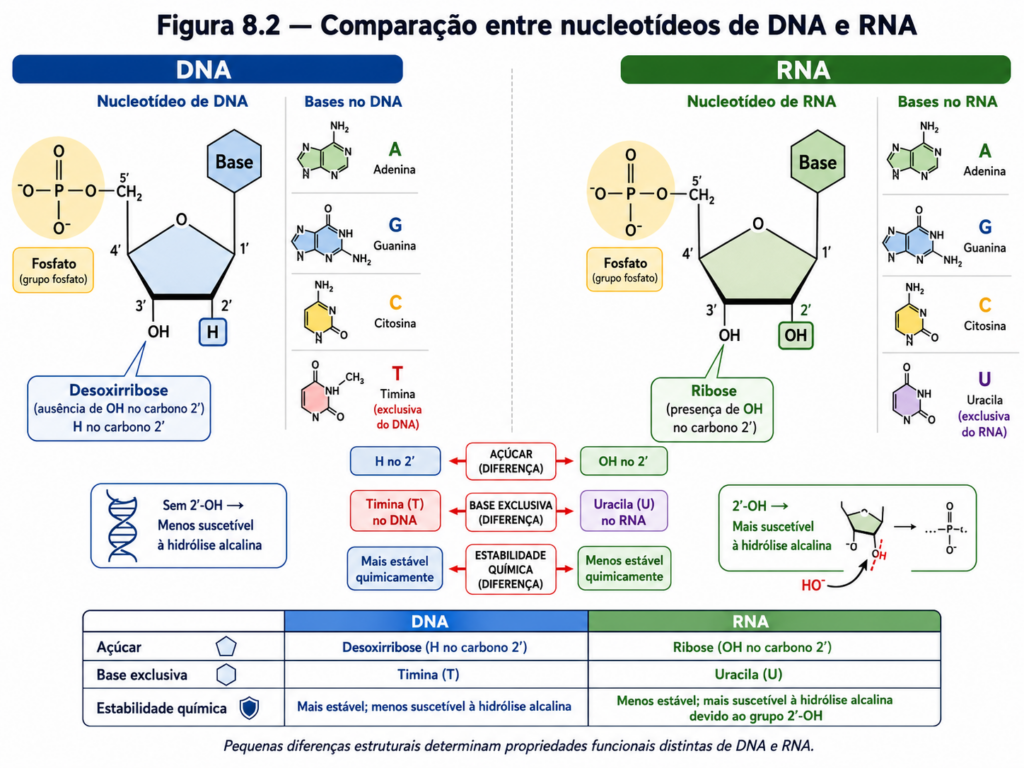
A ligação entre a base nitrogenada e a pentose ocorre por meio de uma ligação N-glicosídica, estabelecida entre o carbono anomérico da pentose (C1’) e um nitrogênio da base (N9 nas purinas e N1 nas pirimidinas). A natureza da pentose define uma distinção central entre os dois principais tipos de ácidos nucleicos: a ribose, presente no RNA, contém um grupo hidroxila no carbono 2’, enquanto a desoxirribose, característica do DNA, carece desse grupo, possuindo apenas um hidrogênio nessa posição. Essa pequena diferença estrutural tem implicações profundas na estabilidade química das moléculas, uma vez que o grupo hidroxila do RNA o torna mais suscetível à hidrólise, especialmente em condições alcalinas [Equação].
Os grupos fosfato, por sua vez, conferem aos nucleotídeos propriedades ácido-base marcantes e são responsáveis pela formação da espinha dorsal dos ácidos nucleicos. Quando ligados ao carbono 5’ da pentose, formam nucleotídeos monofosfatados; a adição de mais grupos fosfato gera nucleotídeos di- e trifosfatados, como ADP e ATP. Esses grupos fosfato estão ionizados em condições fisiológicas, carregando cargas negativas que influenciam tanto a solubilidade quanto a interação dos nucleotídeos com proteínas e íons metálicos. Além disso, a repulsão eletrostática entre fosfatos adjacentes desempenha papel importante na conformação dos ácidos nucleicos e na necessidade de estabilização por cátions, como Mg²⁺ [Figura].
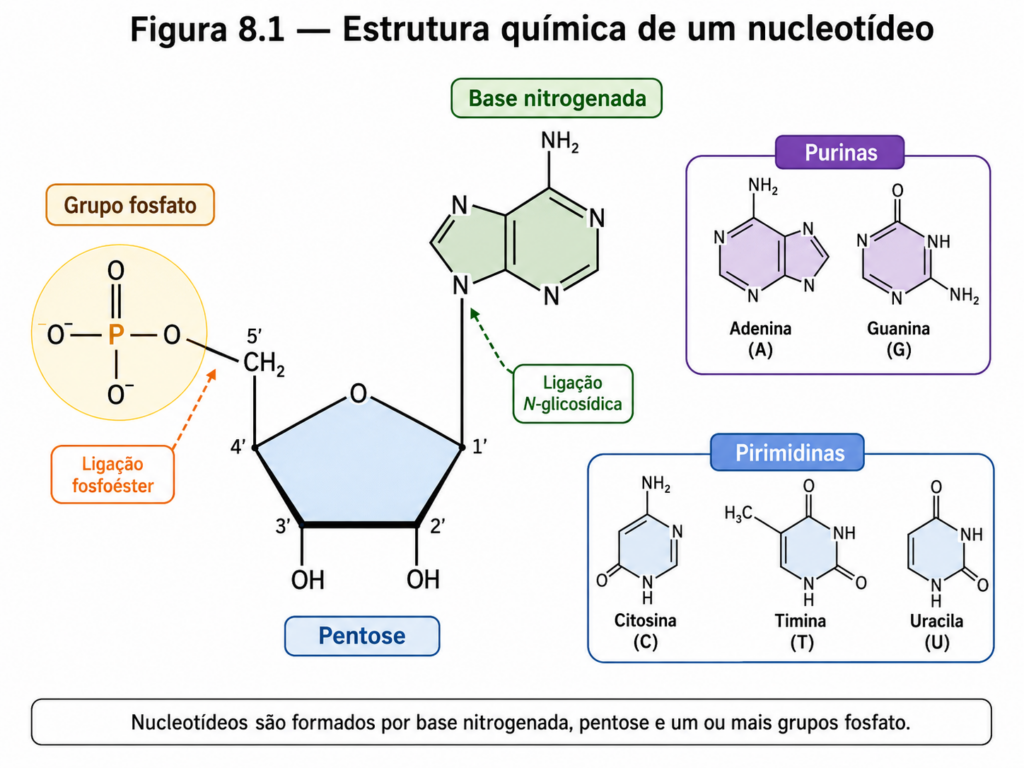
A ligação entre nucleotídeos ocorre por meio de ligações fosfodiéster, estabelecidas entre o grupo fosfato ligado ao carbono 5’ de um nucleotídeo e a hidroxila do carbono 3’ do nucleotídeo adjacente. Esse arranjo confere direcionalidade às cadeias de ácidos nucleicos, definindo a polaridade estrutural 5’ → 3’. Essa orientação não é apenas um detalhe estrutural, mas um princípio organizador que governa todos os processos de replicação e expressão gênica. A síntese de DNA e RNA, por exemplo, ocorre invariavelmente na direção 5’ → 3’, refletindo a química intrínseca dessas ligações [Quadro].
Do ponto de vista termodinâmico, os nucleotídeos assumem um papel adicional como intermediários energéticos. O trifosfato de adenosina (ATP) é o exemplo mais emblemático, atuando como a principal moeda energética da célula. A hidrólise das ligações fosfoanidrido de alta energia libera energia livre suficiente para impulsionar uma ampla variedade de processos bioquímicos, desde a contração muscular até a síntese de macromoléculas. Essa propriedade decorre da combinação de fatores como a repulsão eletrostática entre os grupos fosfato, a estabilização dos produtos de hidrólise e o aumento da entropia do sistema [Equação].
Além de sua função energética, nucleotídeos e seus derivados participam de processos regulatórios e de sinalização celular. Moléculas como AMP cíclico (cAMP) atuam como segundos mensageiros, traduzindo sinais extracelulares em respostas intracelulares específicas. Outros nucleotídeos participam como cofatores em reações metabólicas, como o NAD⁺ e o FAD, que desempenham papéis centrais em reações de oxidorredução. Essa multifuncionalidade reforça a ideia de que os nucleotídeos não são apenas blocos estruturais dos ácidos nucleicos, mas elementos centrais na integração entre informação, energia e metabolismo.
A análise estrutural dos nucleotídeos revela, portanto, uma arquitetura molecular altamente otimizada, na qual pequenas variações químicas resultam em diferenças significativas de função. Essa relação íntima entre estrutura e função antecipa um dos princípios fundamentais da bioquímica: a forma molecular não apenas permite a função, mas a determina. Nos capítulos seguintes, essa base estrutural será expandida para explicar como a informação codificada nesses polímeros é replicada, expressa e regulada, conectando a química dos nucleotídeos à complexidade dos sistemas biológicos.
8.2 Organização estrutural dos ácidos nucleicos: DNA e RNA #
A partir da unidade básica representada pelos nucleotídeos, emerge um dos sistemas estruturais mais sofisticados da biologia: os ácidos nucleicos. A organização dessas macromoléculas não é aleatória nem meramente polimérica; trata-se de uma arquitetura altamente específica, cuja forma tridimensional está diretamente associada à sua função primordial — armazenar, transmitir e expressar informação genética. A compreensão dessa organização exige olhar simultaneamente para os níveis químico, estrutural e funcional, pois é nessa intersecção que o DNA e o RNA adquirem significado biológico.
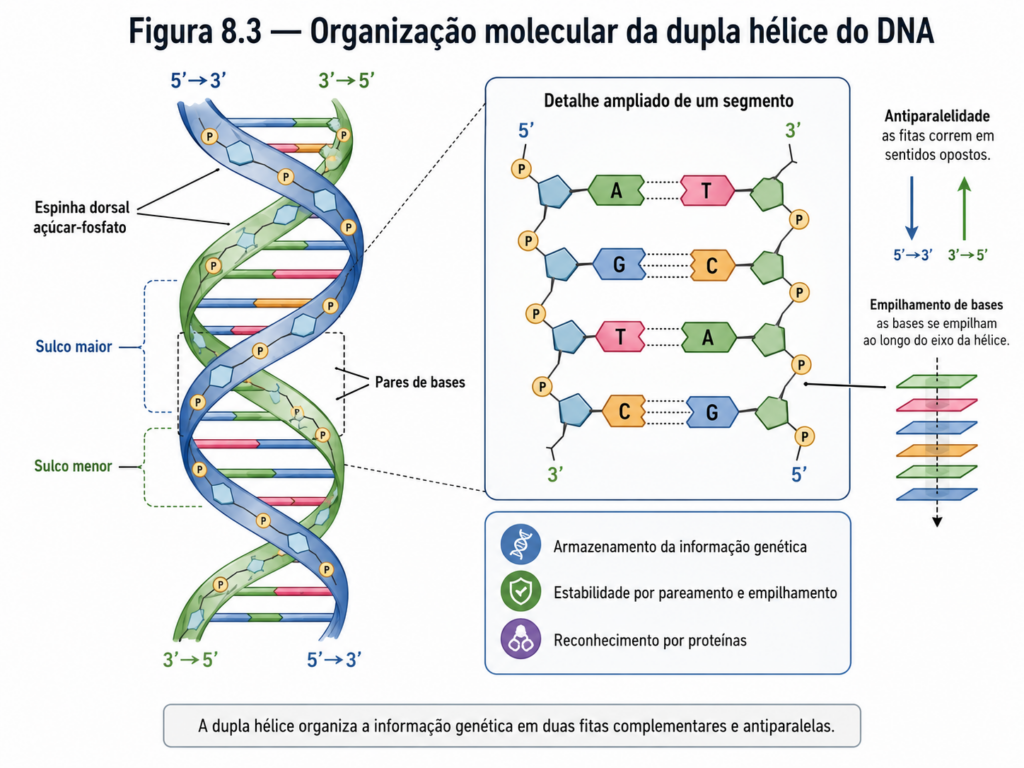
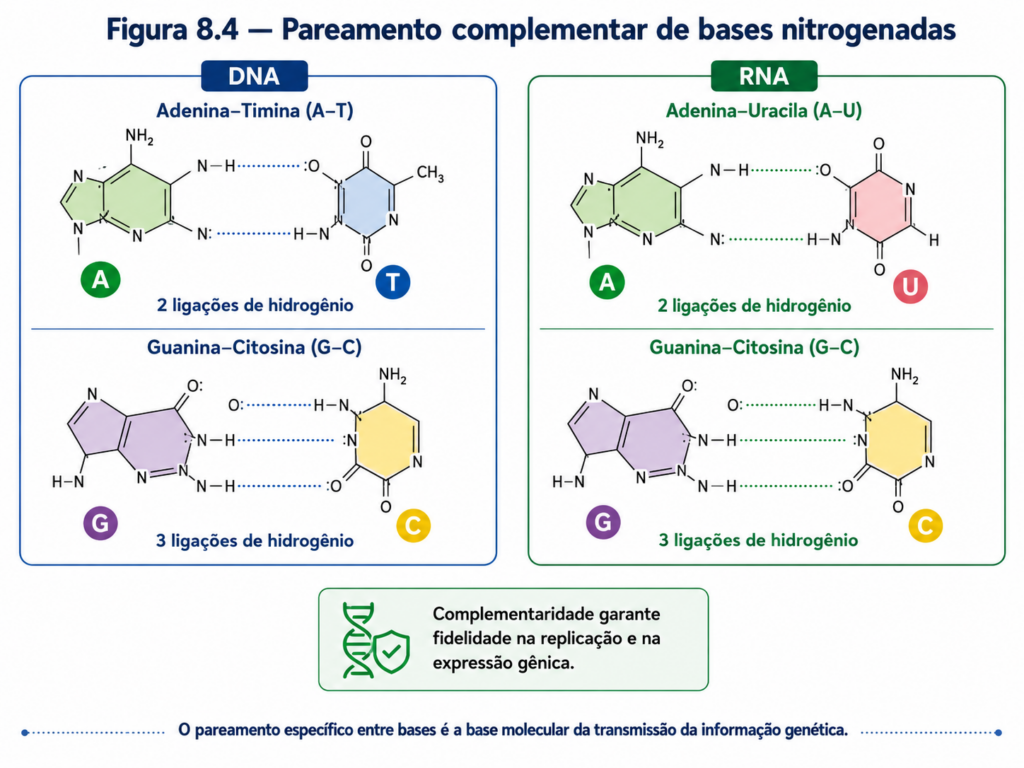
O ácido desoxirribonucleico (DNA) apresenta-se, em sua forma mais clássica, como uma dupla hélice formada por duas cadeias polinucleotídicas antiparalelas. Cada cadeia possui uma orientação definida, com extremidades 5’ e 3’, e ambas se organizam em sentidos opostos, permitindo o alinhamento complementar das bases nitrogenadas. A estabilidade dessa estrutura helicoidal resulta de dois fatores principais: as ligações de hidrogênio entre bases complementares — adenina com timina, guanina com citosina — e as interações de empilhamento entre os anéis aromáticos das bases, que contribuem significativamente para a estabilidade termodinâmica do conjunto [Figura].
A geometria da dupla hélice não é um detalhe trivial. A forma predominante em condições fisiológicas, conhecida como DNA-B, apresenta cerca de 10 pares de bases por volta helicoidal, com sulcos maior e menor bem definidos. Esses sulcos constituem regiões críticas de reconhecimento molecular, onde proteínas reguladoras, como fatores de transcrição, se ligam de maneira altamente específica. Assim, a estrutura do DNA não apenas protege a informação genética, mas também regula seu acesso, estabelecendo uma interface funcional entre sequência e expressão gênica.
Entretanto, o DNA não é estruturalmente estático. Ele pode assumir diferentes conformações, como as formas A e Z, dependendo de condições como hidratação, sequência de bases e ambiente iônico. A forma A é mais compacta e ocorre frequentemente em regiões desidratadas ou em híbridos DNA-RNA, enquanto a forma Z apresenta uma hélice levógira e está associada a sequências ricas em GC. Essas variações estruturais refletem a plasticidade do DNA e sugerem que sua função vai além do armazenamento passivo de informação, envolvendo também mecanismos dinâmicos de regulação [Quadro].
O ácido ribonucleico (RNA), por sua vez, apresenta uma organização estrutural distinta e funcionalmente mais diversificada. Embora também seja formado por nucleotídeos ligados por ligações fosfodiéster, o RNA é geralmente monocatenário. Essa característica, longe de representar uma limitação, confere ao RNA uma notável capacidade de dobramento intramolecular, permitindo a formação de estruturas secundárias e terciárias complexas. Regiões complementares dentro da mesma molécula podem parear, originando estruturas como hastes, alças e pseudonós, que são essenciais para sua função [Figura].
A presença do grupo hidroxila no carbono 2’ da ribose é um fator determinante para essa flexibilidade estrutural. Ele não apenas influencia a conformação espacial da molécula, mas também permite a participação do RNA em reações catalíticas. Diferentemente do DNA, que atua predominantemente como reservatório de informação, o RNA pode desempenhar papéis ativos, como evidenciado pelos ribozimas — moléculas de RNA com atividade enzimática. Esse aspecto reforça a hipótese evolutiva de um “mundo de RNA”, no qual essas moléculas teriam exercido simultaneamente funções informacionais e catalíticas.
A diversidade funcional do RNA se manifesta em suas diferentes classes. O RNA mensageiro (mRNA) atua como intermediário entre o DNA e a síntese proteica, transportando a informação genética na forma de códons. O RNA transportador (tRNA) funciona como adaptador molecular, reconhecendo códons específicos e carregando os aminoácidos correspondentes. Já o RNA ribossomal (rRNA) compõe a estrutura dos ribossomos e participa diretamente da catálise da ligação peptídica. Além desses, uma variedade crescente de RNAs não codificantes exerce funções regulatórias, modulando a expressão gênica em diferentes níveis [Molécula].
Do ponto de vista estrutural, tanto DNA quanto RNA dependem de interações não covalentes para manter sua organização tridimensional. As ligações de hidrogênio garantem a especificidade do pareamento de bases, enquanto as interações hidrofóbicas e de empilhamento conferem estabilidade global. Íons metálicos, especialmente Mg²⁺, desempenham papel crucial na neutralização das cargas negativas dos fosfatos, permitindo o dobramento adequado das moléculas, particularmente no caso do RNA.
A organização estrutural dos ácidos nucleicos revela, portanto, um princípio central da bioquímica: a forma molecular é uma extensão direta da função biológica. No DNA, a estabilidade e a regularidade estrutural favorecem o armazenamento fiel da informação. No RNA, a flexibilidade e a capacidade de dobramento permitem uma diversidade funcional que transcende a simples transmissão de informação. Essa dualidade estrutura–função estabelece a base para os processos que serão explorados nas seções seguintes, nos quais a informação codificada nessas moléculas será replicada, transcrita e traduzida em atividade biológica concreta.
8.3 Código genético e armazenamento da informação biológica #
A organização estrutural dos ácidos nucleicos atinge seu pleno significado quando considerada sob a perspectiva da informação. O DNA não é apenas uma macromolécula estável; ele é, fundamentalmente, um sistema de codificação. A sequência linear de nucleotídeos constitui uma linguagem molecular, na qual combinações específicas de bases nitrogenadas são interpretadas pela maquinaria celular para produzir proteínas. Esse sistema de correspondência entre sequência nucleotídica e sequência de aminoácidos é definido pelo código genético, um dos princípios mais elegantes e conservados da biologia.
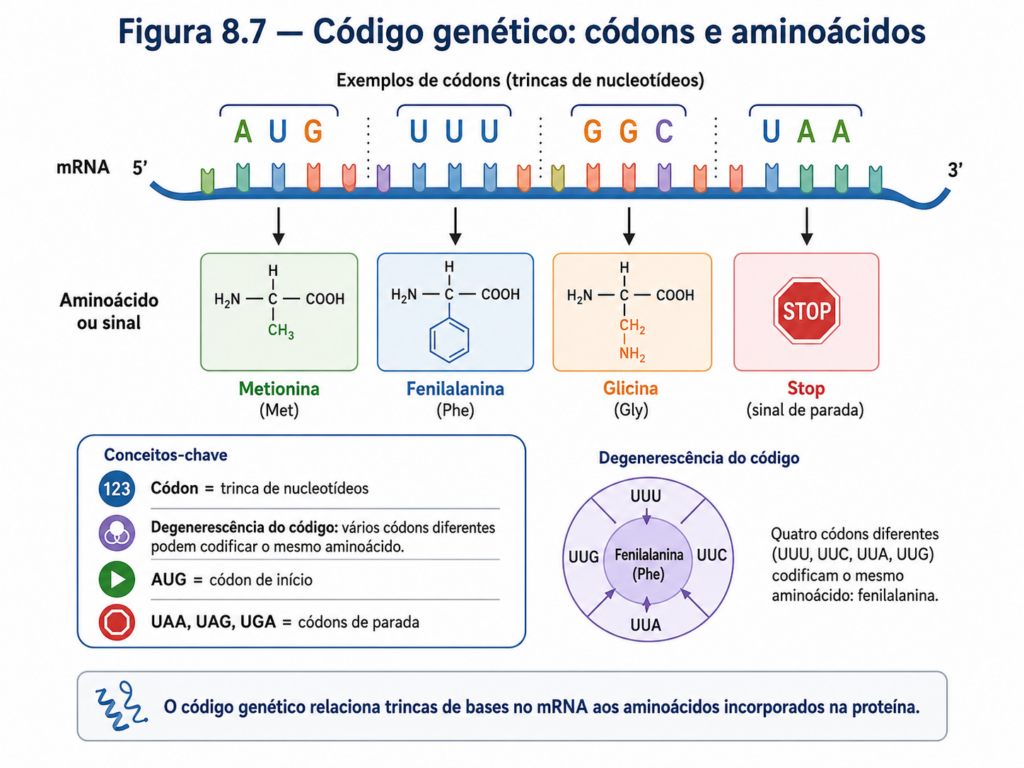
O código genético baseia-se na leitura de trincas de nucleotídeos, denominadas códons. Cada códon, formado por três bases consecutivas no RNA mensageiro, especifica um aminoácido ou um sinal funcional no processo de tradução. A escolha de três nucleotídeos como unidade de codificação não é arbitrária; decorre da necessidade combinatória de representar pelo menos vinte aminoácidos distintos com um número limitado de bases. Com quatro bases possíveis, uma leitura em trincas gera 64 combinações (4³), número suficiente para codificar todos os aminoácidos e ainda incluir sinais de controle, como início e término da tradução [Tabela].
Essa redundância no código, conhecida como degenerescência, constitui uma característica central do sistema. Vários códons podem codificar o mesmo aminoácido, especialmente quando diferem apenas na terceira posição. Essa propriedade tem implicações importantes na estabilidade da informação genética, pois confere certa tolerância a mutações pontuais. Alterações na terceira base frequentemente não resultam em mudanças na sequência de aminoácidos, fenômeno conhecido como mutação silenciosa. Essa robustez estrutural do código contribui para a preservação funcional das proteínas ao longo da evolução.
Apesar dessa redundância, o código genético é altamente específico e não ambíguo: cada códon corresponde a um único aminoácido. Além disso, o código é praticamente universal, sendo compartilhado por organismos de todos os domínios da vida, com poucas variações em sistemas específicos, como mitocôndrias e alguns microrganismos. Essa universalidade reforça a ideia de uma origem comum da vida e destaca o código genético como um dos elementos mais conservados da evolução biológica .
O processo de leitura do código genético ocorre no contexto da tradução, mas sua base conceitual está no armazenamento da informação no DNA. A sequência de bases no DNA é transcrita em RNA mensageiro, preservando a ordem linear dos nucleotídeos, com a substituição da timina por uracila. Esse RNA é então interpretado em blocos de três bases, de forma contínua e não sobreposta, a partir de um códon de iniciação, geralmente AUG, que também codifica o aminoácido metionina. A leitura prossegue até a ocorrência de um dos códons de terminação (UAA, UAG ou UGA), que não codificam aminoácidos, mas sinalizam o fim da síntese proteica [Figura].
A linearidade da informação genética é um aspecto crítico. Ao contrário de linguagens humanas, que possuem pontuação e estruturas hierárquicas explícitas, o código genético é lido de forma contínua, sem separadores entre os códons. Isso implica que a definição do ponto de início da leitura — o “frame” de leitura — é essencial para a correta interpretação da informação. Um deslocamento nesse quadro de leitura, causado por inserções ou deleções de nucleotídeos, pode alterar completamente a sequência de aminoácidos produzida, com consequências frequentemente drásticas para a função proteica.
Além de codificar proteínas, o DNA armazena informações regulatórias fundamentais. Regiões específicas da sequência nucleotídica atuam como sinais de controle para a transcrição, determinando quando, onde e em que intensidade um gene será expresso. Assim, o genoma não é apenas um repositório de instruções estruturais, mas um sistema dinâmico de controle da atividade celular. Essa dimensão regulatória amplia o conceito de informação genética, incorporando não apenas “o que” deve ser produzido, mas também “quando” e “quanto”.
Do ponto de vista químico, a estabilidade do DNA como molécula de armazenamento é notável. A ausência do grupo hidroxila no carbono 2’ da desoxirribose reduz sua suscetibilidade à hidrólise, tornando-o adequado para a conservação de informação ao longo de longos períodos. Ao mesmo tempo, mecanismos de reparo altamente eficientes corrigem danos estruturais, preservando a integridade da sequência genética. Essa combinação de estabilidade e capacidade de reparo garante a fidelidade da transmissão da informação entre gerações celulares.
A relação entre sequência nucleotídica e função biológica constitui um dos pilares da bioquímica moderna. Pequenas variações na sequência podem resultar em alterações significativas na estrutura e na atividade das proteínas, influenciando processos fisiológicos e patológicos. Esse princípio é explorado em diversas áreas aplicadas, desde a engenharia genética até o melhoramento de culturas agrícolas, onde a modificação dirigida de genes permite otimizar características de interesse.
O código genético, portanto, não deve ser entendido apenas como uma tabela de correspondência entre códons e aminoácidos, mas como um sistema integrado de armazenamento, transmissão e interpretação de informação biológica. Ele conecta diretamente a química dos nucleotídeos à complexidade funcional dos organismos, estabelecendo a base conceitual para os processos de replicação, transcrição e tradução que serão aprofundados nas próximas seções.
8.4 Replicação do DNA: mecanismos e fidelidade #
A replicação do DNA representa um dos processos mais críticos da bioquímica, pois sustenta a continuidade da vida ao garantir que a informação genética seja transmitida com alta fidelidade entre gerações celulares. Diferentemente de muitas reações bioquímicas que toleram variações, a replicação exige um nível de precisão excepcional. Um erro não corrigido pode comprometer a função proteica, alterar vias metabólicas e, em última instância, afetar a viabilidade do organismo. Essa exigência moldou um sistema molecular altamente coordenado, no qual múltiplas enzimas atuam de forma integrada para copiar o genoma de maneira eficiente e precisa.
O modelo fundamental da replicação do DNA é descrito como semiconservativo. Nesse mecanismo, cada molécula filha conserva uma das fitas parentais e sintetiza uma nova fita complementar. Esse arranjo não é apenas estruturalmente lógico, mas quimicamente eficiente: a fita original atua como molde, determinando a incorporação correta dos nucleotídeos por meio das regras de pareamento de bases [Figura]. A complementaridade entre adenina e timina, e entre guanina e citosina, estabelece o princípio central da replicação — a informação genética pode ser copiada porque já está codificada na própria estrutura da molécula.
A replicação inicia-se em regiões específicas do DNA, conhecidas como origens de replicação. Nesses pontos, complexos proteicos reconhecem sequências particulares e promovem a abertura da dupla hélice. A separação das fitas é catalisada por enzimas helicases, que rompem as ligações de hidrogênio entre as bases, gerando estruturas conhecidas como forquilhas de replicação. Essa abertura, no entanto, cria tensões topológicas na molécula, que são aliviadas por topoisomerases, enzimas capazes de cortar e religar temporariamente as fitas de DNA, evitando o superenrolamento [Quadro].
Uma vez expostas, as fitas simples tornam-se moldes para a síntese de novas cadeias. A enzima central desse processo é a DNA polimerase, responsável por catalisar a formação de ligações fosfodiéster entre nucleotídeos. Essa reação ocorre sempre na direção 5’ → 3’, adicionando nucleotídeos à extremidade 3’ livre da cadeia em crescimento. Essa restrição direcional tem implicações estruturais profundas: como as duas fitas do DNA são antiparalelas, apenas uma delas pode ser sintetizada de forma contínua, no sentido da abertura da forquilha. Essa fita é denominada fita líder [Figura].
A outra fita, orientada no sentido oposto, é sintetizada de maneira descontínua, em pequenos fragmentos conhecidos como fragmentos de Okazaki. Cada fragmento é iniciado por um pequeno primer de RNA, sintetizado por uma enzima primase, que fornece a extremidade 3’ necessária para a ação da DNA polimerase. Posteriormente, esses primers são removidos, substituídos por DNA e os fragmentos são unidos por ação da DNA ligase, formando uma cadeia contínua. Esse arranjo revela uma solução bioquímica elegante para um problema estrutural imposto pela geometria do DNA.
A fidelidade da replicação depende de múltiplos níveis de controle. O primeiro nível está na própria especificidade da DNA polimerase, que seleciona nucleotídeos complementares com alta precisão. No entanto, erros podem ocorrer, especialmente devido à semelhança estrutural entre algumas bases. Para minimizar essas falhas, muitas DNA polimerases possuem atividade de proofreading, uma função exonucleásica que remove nucleotídeos incorretamente incorporados imediatamente após sua adição. Esse mecanismo reduz drasticamente a taxa de erro, aumentando a confiabilidade do processo [Equação].
Além do proofreading, sistemas de reparo pós-replicativo atuam como uma segunda linha de defesa. Mecanismos como o reparo de pareamento incorreto (mismatch repair) identificam distorções na dupla hélice causadas por bases mal pareadas e corrigem essas anomalias. Outros sistemas, como o reparo por excisão de bases ou nucleotídeos, removem lesões químicas decorrentes de agentes físicos ou químicos. Esses processos garantem que a integridade do genoma seja mantida mesmo diante de agressões constantes ao DNA.
Do ponto de vista cinético, a replicação é um processo altamente eficiente. Em organismos procariotos, a taxa de incorporação de nucleotídeos pode atingir milhares por segundo, enquanto em eucariotos, embora mais lenta, ocorre simultaneamente em múltiplas origens de replicação ao longo dos cromossomos. Essa estratégia permite a duplicação de genomas complexos dentro de intervalos de tempo biologicamente viáveis, como o ciclo celular.
A replicação do DNA não ocorre de forma isolada, mas integrada a um contexto celular mais amplo. Ela está rigidamente controlada ao longo do ciclo celular, sendo iniciada apenas em condições adequadas e uma única vez por ciclo. Esse controle evita replicações redundantes ou incompletas, que poderiam levar a instabilidade genômica. Proteínas regulatórias monitoram o estado do DNA e a disponibilidade de recursos, coordenando a replicação com outros processos celulares, como crescimento e divisão.
A precisão e a eficiência da replicação do DNA refletem um princípio central da bioquímica: sistemas biológicos evoluíram para maximizar a confiabilidade de processos críticos, mesmo em ambientes sujeitos a variações e perturbações. Ao mesmo tempo, a existência de mecanismos que permitem, ainda que raramente, a introdução de variações na sequência genética fornece a base molecular para a evolução. Assim, a replicação não é apenas um processo de conservação, mas também um ponto de equilíbrio entre estabilidade e variabilidade, sustentando tanto a continuidade quanto a diversidade da vida.
8.5 Transcrição: síntese e processamento de RNA #
Se a replicação garante a preservação da informação genética, a transcrição marca o início de sua utilização funcional. É nesse processo que a informação contida no DNA é convertida em uma forma operacional — o RNA — capaz de ser interpretada pela maquinaria celular. A transcrição não é uma simples cópia; trata-se de uma etapa altamente regulada, seletiva e dinâmica, que determina quais segmentos do genoma serão efetivamente expressos em um dado contexto fisiológico.
A transcrição é catalisada pela RNA polimerase, uma enzima que sintetiza RNA a partir de um molde de DNA. Assim como na replicação, a síntese ocorre na direção 5’ → 3’, com a adição de ribonucleotídeos trifosfatados à extremidade 3’ da cadeia em crescimento. No entanto, diferentemente da DNA polimerase, a RNA polimerase não necessita de um primer para iniciar a síntese, sendo capaz de começar a polimerização diretamente a partir de uma sequência promotora específica no DNA [Figura].
O processo inicia-se com o reconhecimento dessas regiões promotoras, que funcionam como sinais de início da transcrição. Em organismos procariotos, a RNA polimerase associa-se a um fator sigma, que facilita a identificação dessas sequências. Em eucariotos, o processo é mais complexo, envolvendo múltiplos fatores de transcrição que formam um complexo de pré-iniciação. Esses fatores reconhecem elementos específicos do DNA, recrutam a RNA polimerase e promovem a abertura local da dupla hélice, formando uma bolha de transcrição [Quadro].
Uma vez iniciada, a RNA polimerase avança ao longo da fita molde de DNA, desenrolando a hélice à frente e religando-a atrás, enquanto sintetiza a molécula de RNA complementar. Apenas uma das fitas de DNA — a fita molde — é utilizada na transcrição, enquanto a outra, denominada fita codificante, possui sequência idêntica ao RNA produzido (com a substituição de timina por uracila). Esse detalhe estrutural é fundamental para compreender a relação entre sequência de DNA e produto final de RNA.
A elongação é caracterizada por alta processividade, com a RNA polimerase mantendo-se firmemente associada ao DNA enquanto incorpora nucleotídeos de forma sequencial. Embora a fidelidade da transcrição seja inferior à da replicação — refletindo menor necessidade de precisão absoluta — ainda assim existem mecanismos que reduzem erros, como pausas na elongação e retrocesso da enzima para remoção de nucleotídeos incorretos [Equação].
A terminação da transcrição ocorre quando a RNA polimerase encontra sinais específicos que indicam o fim do gene. Em procariotos, esses sinais podem ser sequências que formam estruturas de alça no RNA, promovendo a dissociação da enzima, ou depender de fatores proteicos adicionais. Em eucariotos, a terminação está frequentemente associada ao processamento do RNA, envolvendo sinais de poliadenilação e clivagem da molécula recém-sintetizada.
Nos organismos eucariotos, o RNA produzido inicialmente — denominado pré-mRNA — não está pronto para ser traduzido. Ele passa por um conjunto de modificações pós-transcricionais que são essenciais para sua estabilidade, exportação do núcleo e eficiência na tradução. O primeiro desses processos é a adição de um “cap” na extremidade 5’, formado por uma guanosina modificada ligada por uma ponte trifosfato. Esse cap protege o RNA contra degradação e participa do reconhecimento pelo ribossomo.
Na extremidade 3’, ocorre a adição de uma cauda poli-A, composta por uma sequência de adeninas. Essa modificação aumenta a estabilidade do RNA e influencia sua tradução. Entre essas duas extremidades, o pré-mRNA sofre um processo de splicing, no qual regiões não codificantes (íntrons) são removidas e regiões codificantes (éxons) são unidas. Esse processo é mediado por um complexo ribonucleoproteico denominado spliceossomo e pode ocorrer de forma alternativa, permitindo que um único gene origine múltiplas variantes proteicas [Figura].
Essa etapa de processamento introduz um nível adicional de complexidade e regulação na expressão gênica. A possibilidade de splicing alternativo amplia significativamente o repertório proteico sem a necessidade de aumentar o número de genes, um aspecto particularmente relevante em organismos mais complexos. Além disso, a estabilidade e a eficiência de tradução dos RNAs podem ser moduladas por sequências específicas e por interações com proteínas e RNAs regulatórios.
A transcrição, portanto, não deve ser entendida apenas como uma etapa intermediária entre DNA e proteína, mas como um ponto central de controle da atividade celular. A decisão de transcrever ou não um gene, bem como a forma como seu RNA é processado, determina diretamente o perfil funcional da célula. Em condições ambientais distintas — como estresse hídrico em plantas ou alterações metabólicas em tecidos animais — a regulação da transcrição permite ajustes rápidos e específicos na expressão gênica.
Esse processo conecta diretamente a informação genética ao metabolismo e à fisiologia. A capacidade de modular a transcrição é, em última instância, o que permite aos organismos responderem a estímulos, adaptarem-se a mudanças e manterem sua homeostase. Ao transformar informação estática em moléculas funcionais, a transcrição estabelece a ponte entre o potencial genético e a realidade bioquímica da célula.
8.6 Tradução: síntese de proteínas e maquinaria ribossomal #
Se a transcrição converte informação genética em linguagem de RNA, a tradução representa o momento em que essa informação se materializa em função biológica concreta. É nesse processo que a sequência de nucleotídeos, organizada em códons, é interpretada e convertida em uma sequência linear de aminoácidos, dando origem às proteínas. A tradução não é apenas uma etapa final; ela é o ponto de convergência entre informação, estrutura e metabolismo, onde a lógica molecular se transforma em atividade bioquímica.
O centro desse processo é o ribossomo, uma complexa maquinaria ribonucleoproteica composta por RNA ribossomal (rRNA) e proteínas. Estruturalmente, o ribossomo é formado por duas subunidades — uma menor, responsável pelo reconhecimento do mRNA, e uma maior, que catalisa a formação da ligação peptídica. Diferentemente de muitas enzimas clássicas, a atividade catalítica central do ribossomo reside no rRNA, configurando-o como um ribozima. Esse aspecto reforça a ideia de que o RNA não é apenas um intermediário informacional, mas também um agente catalítico ativo [Figura].
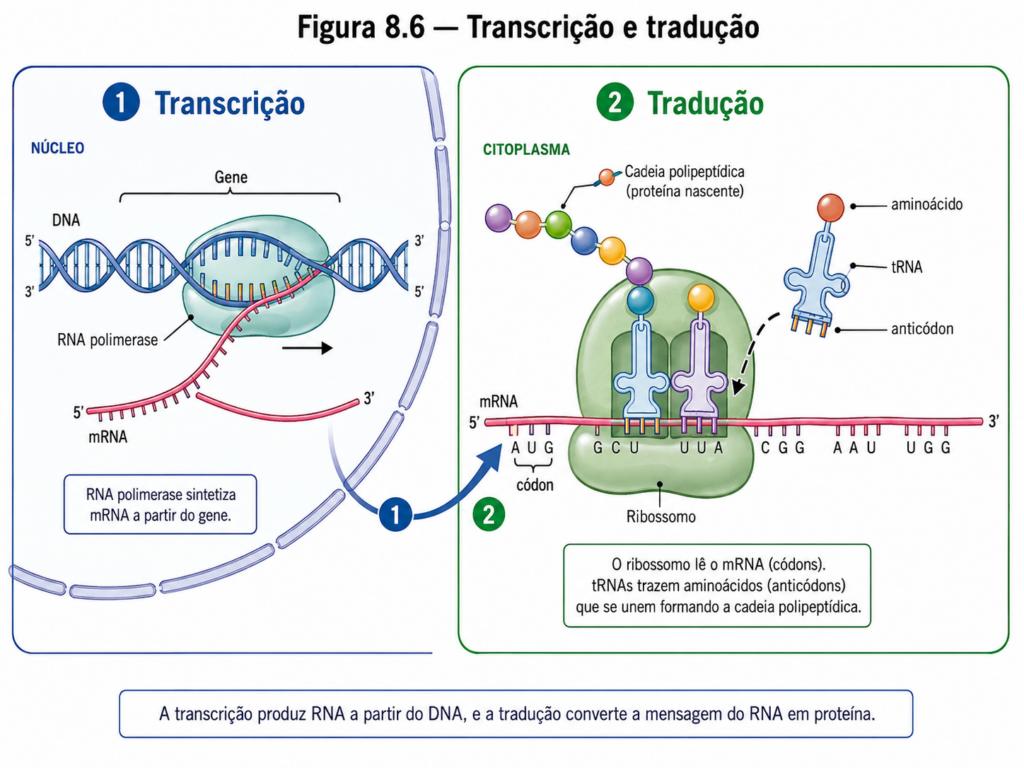
A tradução ocorre no citosol e segue a orientação 5’ → 3’ do mRNA. A leitura do código genético é mediada por moléculas adaptadoras — os RNAs transportadores (tRNAs). Cada tRNA possui duas regiões funcionalmente distintas: um anticódon, que reconhece especificamente um códon no mRNA, e uma extremidade aceitadora, à qual um aminoácido correspondente está ligado. Essa ligação entre tRNA e aminoácido é catalisada por enzimas altamente específicas, as aminoacil-tRNA sintetases, que garantem a fidelidade da correspondência entre código e produto [Molécula].
O processo de tradução pode ser dividido em três etapas principais: iniciação, elongação e terminação. A iniciação começa com o reconhecimento do códon de início, geralmente AUG, pelo tRNA iniciador carregado com metionina. Esse complexo se associa à subunidade menor do ribossomo e ao mRNA, posicionando o códon inicial no sítio correto. Em seguida, a subunidade maior se acopla, formando o ribossomo funcional completo. Esse arranjo define o quadro de leitura que será mantido ao longo de toda a síntese proteica [Quadro].
Durante a elongação, novos tRNAs carregados com aminoácidos entram no ribossomo de acordo com a sequência de códons do mRNA. O ribossomo possui três sítios funcionais: o sítio A (aminoacil), onde o tRNA carregado entra; o sítio P (peptidil), onde se encontra o tRNA que carrega a cadeia polipeptídica em crescimento; e o sítio E (exit), por onde o tRNA descarregado deixa o complexo. A formação da ligação peptídica ocorre entre o aminoácido do sítio A e a cadeia polipeptídica no sítio P, sendo catalisada pelo rRNA da subunidade maior [Figura].
Após a formação da ligação peptídica, o ribossomo sofre um deslocamento ao longo do mRNA — um processo denominado translocação. Esse movimento reposiciona o tRNA carregado do sítio A para o sítio P, liberando o sítio A para a entrada do próximo tRNA. Esse ciclo se repete de forma altamente coordenada e eficiente, permitindo a síntese sequencial da proteína com base na informação codificada no mRNA.
A terminação ocorre quando o ribossomo encontra um códon de parada (UAA, UAG ou UGA). Esses códons não possuem tRNAs correspondentes; em vez disso, são reconhecidos por fatores de liberação, proteínas que promovem a hidrólise da ligação entre a cadeia polipeptídica e o tRNA no sítio P. Como resultado, a proteína recém-sintetizada é liberada, e o ribossomo se dissocia em suas subunidades, pronto para iniciar um novo ciclo de tradução.
A fidelidade da tradução é crítica para a funcionalidade das proteínas. Erros na incorporação de aminoácidos podem comprometer a estrutura tridimensional da proteína e, consequentemente, sua atividade biológica. Essa precisão é garantida principalmente pela especificidade das aminoacil-tRNA sintetases e pelo reconhecimento correto entre códons e anticódons. Ainda assim, o sistema mantém certa flexibilidade, como evidenciado pelo fenômeno de “wobble”, no qual a terceira base do códon pode permitir pareamentos menos rígidos sem comprometer a especificidade global.
Do ponto de vista energético, a tradução é um processo custoso. A formação de cada ligação peptídica consome energia proveniente da hidrólise de nucleotídeos trifosfatados, principalmente GTP. Esse investimento energético reflete a importância biológica do processo e garante sua irreversibilidade e direção correta. Além disso, a energia envolvida contribui para a precisão e para o controle das etapas da tradução.
A tradução não ocorre isoladamente; ela está integrada a sistemas de regulação que determinam quais mRNAs serão traduzidos, em que quantidade e em quais condições. Em muitos casos, múltiplos ribossomos podem se associar a uma mesma molécula de mRNA, formando polissomos, o que aumenta a eficiência da síntese proteica. Por outro lado, mecanismos regulatórios podem bloquear a tradução em resposta a sinais celulares, ajustando rapidamente o perfil proteico da célula.
Ao final desse processo, a sequência linear de aminoácidos sintetizada começa a se dobrar espontaneamente ou com auxílio de chaperonas, adquirindo uma estrutura tridimensional funcional. Assim, a tradução não apenas encerra o fluxo de informação genética, mas inaugura o domínio da função bioquímica, onde proteínas passam a atuar como enzimas, estruturas, transportadores e reguladores.
A tradução representa, portanto, a etapa em que a bioquímica atinge sua expressão mais concreta: a transformação de informação molecular em atividade biológica. É nesse ponto que o genoma deixa de ser potencial e se torna realidade funcional, conectando diretamente a sequência de nucleotídeos ao metabolismo, à fisiologia e à adaptação dos sistemas vivos.
8.7 Regulação da expressão gênica #
A existência de um código genético universal e de uma maquinaria eficiente de replicação, transcrição e tradução não implica que todos os genes sejam expressos continuamente. Pelo contrário, a característica mais crítica dos sistemas biológicos é a capacidade de controlar seletivamente a expressão gênica, ajustando a produção de RNAs e proteínas às condições ambientais, ao estado metabólico e ao tipo celular. A regulação da expressão gênica é, portanto, o verdadeiro ponto de controle da bioquímica: é aqui que o potencial genético é convertido em resposta adaptativa.
Em termos conceituais, regular a expressão gênica significa controlar quando, onde e em que intensidade um gene é expresso. Esse controle pode ocorrer em múltiplos níveis, mas o mais determinante é o nível transcricional, onde se decide se um gene será ou não transcrito. Em organismos procariotos, esse controle é frequentemente organizado em unidades funcionais chamadas operons, nos quais múltiplos genes são regulados por uma única região promotora. Sistemas como o operon lac exemplificam como a presença ou ausência de um substrato pode modular diretamente a transcrição, permitindo respostas rápidas e eficientes ao ambiente.
Em eucariotos, a regulação é substancialmente mais complexa e distribuída. O DNA encontra-se organizado em cromatina, uma estrutura dinâmica composta por DNA associado a proteínas histonas. O grau de compactação da cromatina determina a acessibilidade do DNA à maquinaria de transcrição. Regiões mais condensadas (heterocromatina) são geralmente transcricionalmente inativas, enquanto regiões mais abertas (eucromatina) são permissivas à expressão gênica. Modificações químicas nas histonas, como acetilação e metilação, alteram essa organização estrutural, funcionando como sinais epigenéticos que modulam a expressão sem alterar a sequência de DNA [Figura].
Além da organização estrutural, elementos regulatórios específicos no DNA desempenham papel central. Promotores, enhancers e silenciadores são sequências que interagem com proteínas reguladoras — os fatores de transcrição. Esses fatores reconhecem padrões específicos na sequência nucleotídica e podem ativar ou reprimir a transcrição ao recrutar ou bloquear a RNA polimerase. A combinação desses fatores gera um controle altamente específico e combinatório, permitindo que diferentes células, mesmo com o mesmo genoma, expressem conjuntos distintos de genes [Quadro].
A regulação não se limita à transcrição. Após a síntese do RNA, diversos mecanismos modulam sua estabilidade, processamento e tradução. O splicing alternativo, por exemplo, permite que um único gene produza múltiplas variantes de RNA e, consequentemente, diferentes proteínas. Esse mecanismo amplia significativamente a diversidade funcional sem necessidade de expansão genômica, sendo particularmente relevante em organismos mais complexos.
Outro nível crítico de regulação envolve os RNAs não codificantes, especialmente microRNAs (miRNAs) e small interfering RNAs (siRNAs). Essas pequenas moléculas de RNA atuam ligando-se a mRNAs específicos e promovendo sua degradação ou inibindo sua tradução. Esse mecanismo permite um controle fino e rápido da expressão gênica, funcionando como um sistema de ajuste pós-transcricional que responde a mudanças fisiológicas e ambientais.
No nível translacional, a regulação pode ocorrer por meio da modulação da eficiência de iniciação da tradução, da disponibilidade de ribossomos ou da interação com proteínas reguladoras. Em condições de estresse, por exemplo, a célula pode reduzir globalmente a tradução, ao mesmo tempo em que aumenta a produção de proteínas específicas necessárias para a adaptação. Esse controle dinâmico conecta diretamente a expressão gênica ao estado metabólico da célula.
A regulação também se estende ao nível pós-traducional. Uma vez sintetizadas, as proteínas podem ser modificadas quimicamente — por fosforilação, acetilação, ubiquitinação, entre outras — alterando sua atividade, localização ou estabilidade. Embora esse nível não altere a expressão gênica no sentido clássico, ele modula o impacto funcional dos produtos gênicos, completando o ciclo de controle da informação biológica.
Do ponto de vista sistêmico, a regulação da expressão gênica é o mecanismo que permite a integração entre genoma e ambiente. Em plantas, por exemplo, a expressão de genes relacionados à fotossíntese, crescimento ou resistência ao estresse hídrico é modulada por sinais ambientais como luz, temperatura e disponibilidade de água. Em organismos animais, hormônios e sinais intracelulares desempenham papel equivalente, ajustando o metabolismo e a função celular conforme as demandas fisiológicas.
Essa capacidade de regulação é também a base de processos complexos como diferenciação celular, desenvolvimento e adaptação evolutiva. Células especializadas emergem não porque possuem genes diferentes, mas porque expressam genes distintos em padrões específicos. Da mesma forma, alterações na regulação gênica podem levar a estados patológicos, como câncer, onde a expressão descontrolada de genes resulta em proliferação celular desordenada.
A regulação da expressão gênica representa, portanto, o verdadeiro nível de inteligência do sistema biológico. É nesse ponto que a bioquímica transcende a estrutura e a função isoladas e se torna um sistema dinâmico, capaz de interpretar sinais, tomar decisões e adaptar-se continuamente. Ao conectar o fluxo de informação genética ao contexto metabólico e ambiental, a regulação estabelece o elo final entre o genoma e o fenótipo, preparando o terreno para a compreensão integrada dos sistemas biológicos.
8.8 Mutações, reparo de DNA e implicações biológicas #
A replicação e a expressão do material genético operam sob um princípio central: a preservação da informação. No entanto, nenhum sistema molecular é absolutamente imune a falhas. Alterações na sequência de nucleotídeos — denominadas mutações — constituem eventos inevitáveis, decorrentes tanto de erros intrínsecos do metabolismo celular quanto da ação de agentes externos. Essas variações representam um ponto de tensão fundamental na bioquímica: ao mesmo tempo em que ameaçam a estabilidade do genoma, são também a base da diversidade biológica e da evolução.
As mutações podem ser classificadas de acordo com sua natureza estrutural. As mutações pontuais envolvem a substituição de uma única base, podendo ser transições (purina por purina ou pirimidina por pirimidina) ou transversões (purina por pirimidina ou vice-versa). Inserções e deleções, por sua vez, alteram o número de nucleotídeos na sequência, podendo causar deslocamentos no quadro de leitura (frameshift), com consequências profundas para a proteína resultante. Em muitos casos, uma única alteração pode modificar completamente a estrutura tridimensional da proteína, comprometendo sua função [Figura].
Do ponto de vista funcional, as mutações podem ser silenciosas, quando não alteram o aminoácido codificado; missense, quando resultam na substituição de um aminoácido por outro; ou nonsense, quando introduzem um códon de parada prematuro. A magnitude do efeito depende não apenas do tipo de mutação, mas também de sua localização na sequência e do papel estrutural do aminoácido afetado. Em regiões críticas, como sítios ativos de enzimas ou domínios estruturais essenciais, pequenas alterações podem ter efeitos desproporcionais.
As origens das mutações são diversas. Erros durante a replicação do DNA, embora raros devido aos mecanismos de proofreading, podem resultar em incorporação incorreta de nucleotídeos. Além disso, o DNA está constantemente exposto a agentes físicos e químicos, como radiação ultravioleta, radiações ionizantes e compostos reativos, que podem induzir modificações químicas nas bases. Processos metabólicos normais também geram espécies reativas de oxigênio, capazes de oxidar nucleotídeos e comprometer a integridade do genoma [Quadro].
Diante desse cenário, as células desenvolveram um conjunto sofisticado de sistemas de reparo de DNA, que atuam de forma contínua para identificar e corrigir danos. Um dos mecanismos mais básicos é o reparo por excisão de bases, no qual enzimas específicas reconhecem bases alteradas, removem-nas e preenchem a lacuna com nucleotídeos corretos. Em casos onde o dano envolve distorções mais extensas na dupla hélice, como dímeros de timina induzidos por radiação UV, entra em ação o reparo por excisão de nucleotídeos, que remove segmentos maiores da cadeia e os substitui por sequências corretas [Figura].
Outro mecanismo crucial é o reparo de pareamento incorreto (mismatch repair), que atua após a replicação, corrigindo erros que escaparam ao proofreading das DNA polimerases. Esse sistema distingue a fita recém-sintetizada da fita molde e remove nucleotídeos incorretamente pareados, restaurando a sequência original. A eficiência desses mecanismos é tal que a taxa final de erro na replicação do DNA é extremamente baixa, garantindo alta fidelidade na transmissão da informação genética.
Quando ocorrem quebras na dupla fita de DNA, consideradas uma das formas mais graves de dano, mecanismos específicos como a recombinação homóloga e a junção de extremidades não homólogas são ativados. A recombinação homóloga utiliza uma sequência intacta como molde para restaurar a região danificada com alta precisão, enquanto a junção de extremidades não homólogas liga diretamente as extremidades quebradas, podendo introduzir pequenas alterações. A escolha entre esses mecanismos depende do contexto celular e da disponibilidade de sequências homólogas.
Apesar da eficiência dos sistemas de reparo, nem todas as mutações são corrigidas. Quando persistem, podem ser transmitidas às células-filhas e, em organismos multicelulares, contribuir para processos patológicos. Muitas doenças genéticas resultam de mutações específicas que alteram a função de proteínas essenciais. Em contextos como o câncer, a acumulação progressiva de mutações em genes que regulam o ciclo celular e a apoptose leva à perda de controle sobre a proliferação celular.
Por outro lado, as mutações também desempenham um papel positivo na biologia. Elas constituem a fonte primária de variabilidade genética, permitindo que populações se adaptem a mudanças ambientais ao longo do tempo. A seleção natural atua sobre essas variações, favorecendo aquelas que conferem vantagens adaptativas. Assim, o mesmo processo que pode gerar disfunção em nível individual é essencial para a evolução em nível populacional.
No contexto aplicado, a compreensão dos mecanismos de mutação e reparo tem implicações diretas em áreas como biotecnologia, melhoramento genético e medicina. Técnicas de edição genômica exploram esses mecanismos para introduzir modificações específicas no DNA, permitindo o desenvolvimento de culturas agrícolas mais resistentes ou a correção de mutações associadas a doenças. Ao mesmo tempo, agentes quimioterápicos frequentemente atuam interferindo nos sistemas de replicação ou reparo, explorando a vulnerabilidade de células tumorais.
A dinâmica entre dano, reparo e mutação revela um princípio central da bioquímica: a vida depende de um equilíbrio delicado entre estabilidade e mudança. A integridade do genoma é continuamente desafiada, mas também continuamente restaurada. Nesse processo, a célula não apenas preserva sua identidade, mas também mantém aberta a possibilidade de inovação biológica.
8.9 Vitaminas como cofatores no metabolismo bioquímico #
Embora frequentemente tratadas como micronutrientes, as vitaminas ocupam uma posição central na bioquímica celular. Sua importância não está na quantidade, mas na função: atuam como precursores de cofatores e coenzimas indispensáveis à atividade enzimática. Em termos práticos, isso significa que grande parte das reações metabólicas — especialmente aquelas envolvidas em transferência de elétrons, grupos químicos e energia — depende diretamente da presença dessas moléculas. Sem vitaminas, o metabolismo não para por falta de substrato, mas por incapacidade catalítica.
As vitaminas são tradicionalmente classificadas em dois grupos principais, com base em sua solubilidade: hidrossolúveis e lipossolúveis. Essa distinção não é meramente didática; ela reflete diferenças profundas na absorção, armazenamento e função bioquímica dessas moléculas.
As vitaminas hidrossolúveis, especialmente as do complexo B, estão diretamente envolvidas em reações metabólicas centrais. Muitas delas são convertidas em coenzimas que participam de processos de oxidorredução, transferência de grupos funcionais e rearranjos moleculares. A niacina (vitamina B3), por exemplo, dá origem ao NAD⁺ (nicotinamida adenina dinucleotídeo), um cofator essencial em reações de desidrogenação. O NAD⁺ atua como transportador de elétrons, sendo reduzido a NADH em diversas etapas do metabolismo energético, como na glicólise e no ciclo do ácido cítrico [Molécula].

De forma semelhante, a riboflavina (vitamina B2) é precursora do FAD (flavina adenina dinucleotídeo), outro cofator redox que participa de reações de oxidação mais complexas, frequentemente associadas a enzimas ligadas à cadeia respiratória. O ácido pantotênico (vitamina B5) compõe a estrutura da coenzima A (CoA), fundamental na transferência de grupos acila, particularmente na formação e oxidação de acetil-CoA, um dos principais intermediários metabólicos. Esses exemplos evidenciam que as vitaminas não são apenas auxiliares, mas componentes estruturais de sistemas enzimáticos essenciais [Figura].
Outras vitaminas hidrossolúveis atuam em reações de transferência de grupos específicos. A tiamina (vitamina B1), na forma de pirofosfato de tiamina (TPP), participa de descarboxilações oxidativas, como na conversão de piruvato em acetil-CoA. A piridoxina (vitamina B6), convertida em fosfato de piridoxal (PLP), está envolvida no metabolismo de aminoácidos, catalisando reações como transaminação e descarboxilação. Já o ácido fólico (vitamina B9) e a cobalamina (vitamina B12) desempenham papéis críticos no metabolismo de unidades de um carbono, sendo essenciais para a síntese de nucleotídeos e, portanto, para a replicação e expressão gênica.
A vitamina C (ácido ascórbico), embora não atue como coenzima clássica, funciona como agente redutor em diversas reações, incluindo a hidroxilação de resíduos de prolina no colágeno. Sua deficiência compromete a integridade estrutural de tecidos, evidenciando como uma única molécula pode impactar diretamente a organização macromolecular.
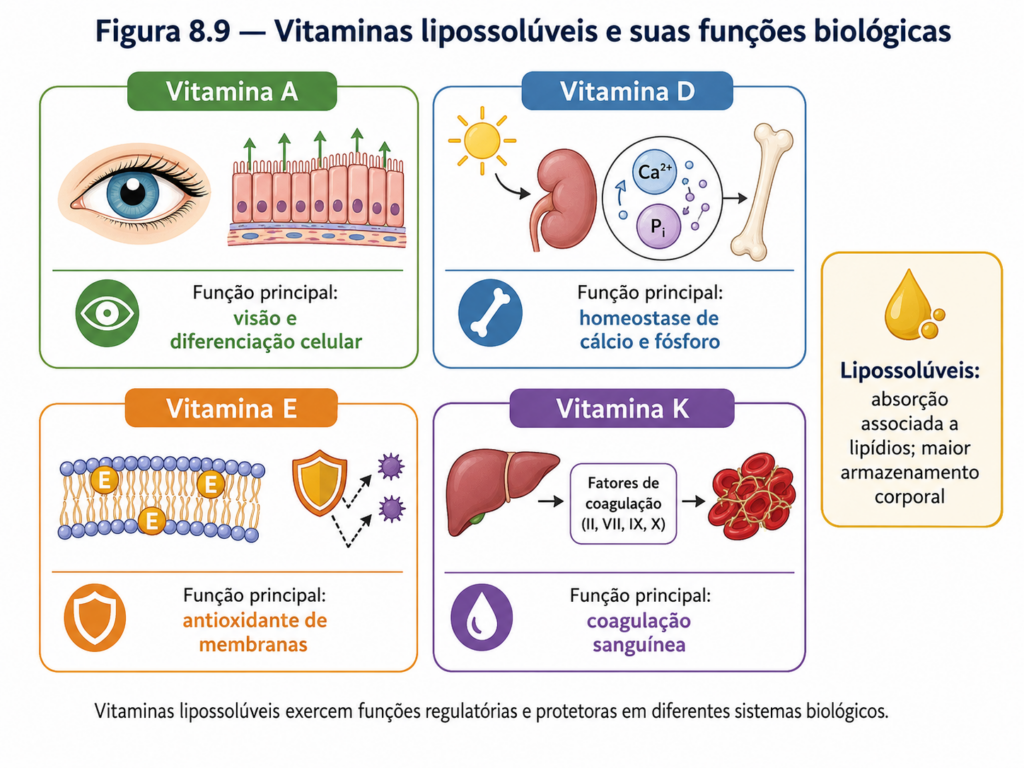
As vitaminas lipossolúveis — A, D, E e K — apresentam funções distintas, frequentemente associadas à regulação e proteção celular. A vitamina A, na forma de retinol ou retinal, está envolvida na visão e na regulação da expressão gênica. A vitamina D atua como um hormônio, regulando o metabolismo de cálcio e fósforo. A vitamina E desempenha papel antioxidante, protegendo membranas lipídicas contra danos oxidativos. Já a vitamina K é essencial para a coagulação sanguínea, participando da ativação de proteínas envolvidas nesse processo [Quadro].
Do ponto de vista bioquímico, a principal característica das vitaminas é sua incapacidade de serem sintetizadas em quantidades suficientes por muitos organismos, especialmente animais. Isso impõe uma dependência direta da dieta para a manutenção das funções metabólicas. Em plantas e microrganismos, muitas dessas vias biossintéticas estão presentes, o que abre possibilidades estratégicas no contexto agronômico, como a biofortificação de culturas para aumentar o conteúdo vitamínico de alimentos.
A deficiência de vitaminas resulta em disfunções metabólicas específicas, frequentemente associadas à perda de atividade de enzimas dependentes de cofatores. Por exemplo, a deficiência de niacina compromete reações redox, afetando a produção de energia. A falta de vitamina B12 interfere na síntese de DNA, impactando células de alta taxa proliferativa. Esses efeitos não são difusos, mas refletem diretamente os pontos de inserção bioquímica de cada vitamina no metabolismo [Figura].
Por outro lado, o excesso de vitaminas, especialmente as lipossolúveis, pode levar à toxicidade, uma vez que essas moléculas são armazenadas no organismo e não são facilmente excretadas. Esse aspecto reforça a necessidade de equilíbrio, não apenas em termos quantitativos, mas também funcionais.
No contexto integrado da bioquímica, as vitaminas funcionam como conectores entre diferentes vias metabólicas. Elas permitem que enzimas realizem reações que, de outra forma, seriam energeticamente desfavoráveis ou quimicamente inviáveis em condições fisiológicas. Ao viabilizar essas transformações, as vitaminas sustentam o fluxo metabólico e garantem a continuidade dos processos bioquímicos essenciais.
A análise das vitaminas como cofatores revela, portanto, um princípio crítico: a eficiência do metabolismo não depende apenas da presença de substratos e enzimas, mas da disponibilidade de moléculas intermediárias que viabilizam a catálise. Sem essas pequenas moléculas, o sistema bioquímico perde sua capacidade operacional, evidenciando que, em biologia, o funcionamento depende tanto das grandes estruturas quanto dos detalhes moleculares mais sutis.
8.10 Integração: do gene ao metabolismo celular #
Ao longo deste capítulo, diferentes níveis da organização bioquímica foram analisados de forma progressiva — da estrutura dos nucleotídeos à expressão gênica e à função das vitaminas como cofatores. No entanto, a compreensão plena desses elementos só se consolida quando eles são integrados em um único sistema funcional. A célula não opera em compartimentos isolados; ela funciona como uma rede dinâmica, onde informação genética, atividade enzimática e fluxo metabólico estão profundamente interconectados.
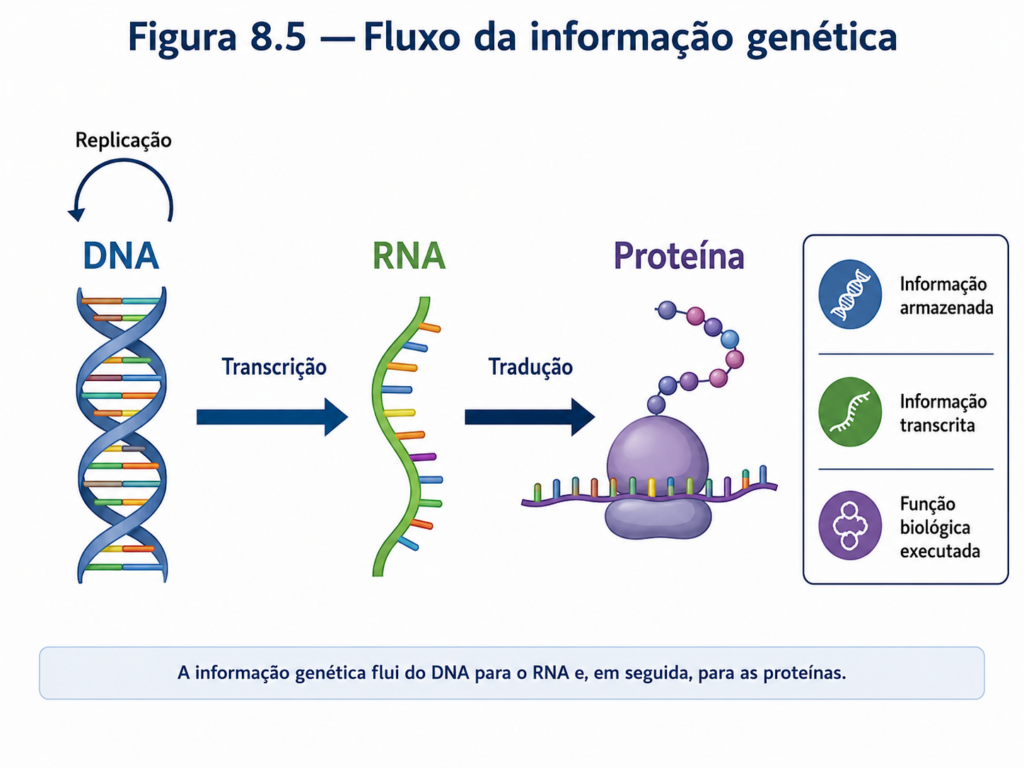
O eixo central dessa integração é o fluxo da informação genética, frequentemente resumido no modelo DNA → RNA → proteína. Essa sequência, embora conceitualmente linear, sustenta uma rede altamente complexa de interações. O DNA armazena a informação em uma forma estável e duradoura. A transcrição converte essa informação em RNA, tornando-a acessível e operacional. A tradução, por sua vez, transforma essa informação em proteínas, que executam funções estruturais, catalíticas e regulatórias. Esse fluxo não é apenas uma cadeia de eventos, mas um sistema regulado em múltiplos níveis, onde cada etapa pode ser modulada conforme as necessidades celulares [Figura].
As proteínas resultantes desse processo são, em grande parte, enzimas. Elas catalisam as reações químicas que constituem o metabolismo, desde a degradação de nutrientes até a biossíntese de macromoléculas. Assim, a expressão gênica determina diretamente o perfil enzimático da célula, e, consequentemente, sua capacidade metabólica. Uma alteração na expressão de um único gene pode modificar o fluxo de uma via metabólica inteira, redirecionando intermediários e alterando o balanço energético [Quadro].
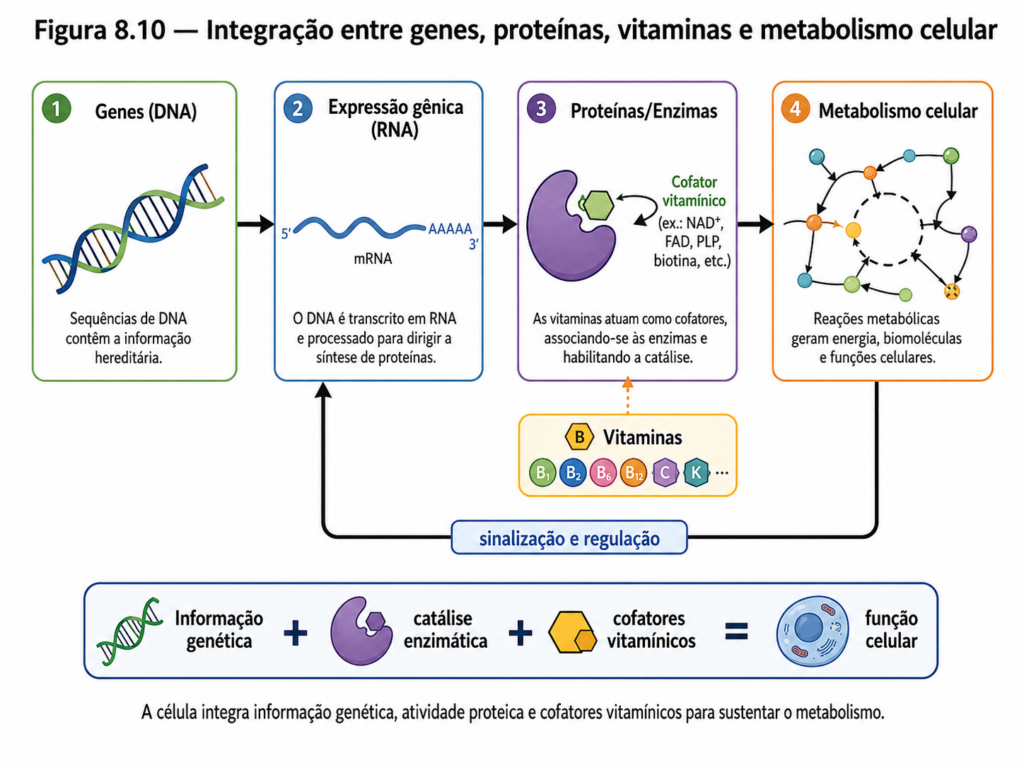
Nesse contexto, as vitaminas desempenham um papel integrador essencial. Como precursores de cofatores, elas permitem que enzimas específicas realizem suas funções catalíticas. Sem NAD⁺, FAD, CoA ou outras coenzimas derivadas de vitaminas, muitas reações metabólicas simplesmente não ocorreriam. Isso significa que a eficiência do metabolismo depende não apenas da expressão gênica, mas também da disponibilidade desses cofatores. A integração entre genes, proteínas e vitaminas estabelece, portanto, um sistema funcional contínuo, no qual cada componente depende do outro para operar adequadamente.
A regulação da expressão gênica conecta esse sistema ao ambiente. Sinais externos — como disponibilidade de nutrientes, condições de estresse ou estímulos hormonais — são traduzidos em alterações na expressão de genes específicos. Em plantas, por exemplo, a limitação hídrica pode induzir a expressão de genes associados à síntese de proteínas de proteção e ajuste osmótico. Em organismos animais, alterações na disponibilidade de glicose modulam a expressão de enzimas envolvidas no metabolismo energético. Esses ajustes permitem que o metabolismo se adapte de forma rápida e eficiente às condições externas.
Além disso, o metabolismo retroalimenta a expressão gênica. Metabólitos intermediários podem atuar como sinais regulatórios, influenciando diretamente a atividade de fatores de transcrição ou a estabilidade de RNAs. Esse mecanismo cria circuitos de controle nos quais a atividade metabólica e a expressão gênica se regulam mutuamente, formando sistemas de feedback que mantêm a homeostase celular.
A integração também se manifesta na compartimentalização celular. Em eucariotos, processos como replicação e transcrição ocorrem no núcleo, enquanto a tradução e grande parte do metabolismo acontecem no citosol e em organelas específicas, como mitocôndrias e cloroplastos. Essa organização espacial permite maior controle e eficiência, evitando interferências entre processos e permitindo especialização funcional [Figura].
Do ponto de vista sistêmico, a célula pode ser entendida como uma rede de fluxo de matéria, energia e informação. O DNA fornece o plano estrutural, o RNA atua como intermediário operacional, as proteínas executam as funções e os cofatores viabilizam as reações. Alterações em qualquer um desses níveis reverberam por todo o sistema. Uma mutação no DNA pode alterar a estrutura de uma enzima, que por sua vez modifica uma via metabólica, impactando o estado fisiológico do organismo.
Essa visão integrada é particularmente relevante em aplicações práticas. Na agricultura, a manipulação da expressão gênica pode aumentar a eficiência metabólica de plantas, melhorando produtividade e resistência a estresses. Na medicina, a compreensão das interações entre genes, proteínas e metabolismo permite identificar alvos terapêuticos e desenvolver intervenções mais precisas. Em biotecnologia, a engenharia de vias metabólicas depende diretamente da capacidade de coordenar esses diferentes níveis de organização.
A integração do fluxo genético com o metabolismo revela, portanto, o verdadeiro escopo da bioquímica: não apenas descrever moléculas ou reações isoladas, mas compreender sistemas vivos como redes organizadas e adaptativas. É essa perspectiva que permite avançar da análise estrutural para a aplicação funcional, preparando o terreno para os capítulos seguintes, onde enzimas, cinética e metabolismo serão explorados como manifestações diretas dessa integração molecular.
Questões de estudo dirigido — Capítulo 8 #
Ácidos Nucleicos, Fluxo da Informação Genética e Cofatores Vitamínicos
- Explique a estrutura química de um nucleotídeo, identificando seus três componentes principais e descrevendo como a base nitrogenada, a pentose e o grupo fosfato contribuem para a formação de DNA e RNA.
- Compare DNA e RNA do ponto de vista estrutural e funcional. Inclua na resposta as diferenças entre desoxirribose e ribose, timina e uracila, estabilidade química e principais funções celulares.
- Descreva como a estrutura da dupla hélice do DNA permite o armazenamento e a transmissão da informação genética. Relacione complementaridade de bases, antiparalelismo, pareamento A–T/G–C e fidelidade molecular.
- Explique o fluxo da informação genética DNA → RNA → proteína. Diferencie replicação, transcrição e tradução, destacando as principais moléculas envolvidas em cada etapa.
- Analise o papel das vitaminas como cofatores metabólicos. Escolha três vitaminas do complexo B e explique quais coenzimas derivam delas, em que tipos de reações atuam e por que sua deficiência pode comprometer o metabolismo celular.
Pergunta para estimular pesquisa #
Como alterações na expressão gênica e na disponibilidade de cofatores vitamínicos podem influenciar a adaptação de plantas ao estresse ambiental, como seca, salinidade ou deficiência nutricional?
Essa pergunta é boa porque força o estudante a conectar ácidos nucleicos, regulação gênica, enzimas, vitaminas e metabolismo vegetal, exatamente a ponte conceitual mais importante deste capítulo dentro da disciplina. A semana 8 foi planejada para integrar DNA, RNA, fluxo da informação genética e vitaminas como cofatores , e o modelo geral do capítulo recomenda fechar com integração sistêmica e aplicações práticas em agro, biotecnologia, ecologia e produção .
Referências #
NELSON, David L.; COX, Michael M. Princípios de bioquímica de Lehninger. 6. ed. Porto Alegre: Artmed, 2014.
VOET, Donald; VOET, Judith G.; PRATT, Charlotte W. Fundamentos de bioquímica: a vida em nível molecular. 4. ed. Porto Alegre: Artmed, 2014.
STRYER, Lubert; BERG, Jeremy M.; TYMOCZKO, John L.; GATTO JR., Gregory J. Bioquímica. 8. ed. Rio de Janeiro: Guanabara Koogan, 2014.
MURRAY, Robert K. et al. Bioquímica ilustrada de Harper. 30. ed. Porto Alegre: AMGH, 2017.



